Core concepts
LLM
LLMs seem to be everywhere today. And we've got tons of them here too for you to use.
Read below to understand how we integrate LLMs into the platform so you have a wide variety of choices for running your Threads.
What you will learn
- How we integrate LLMs into Threads
Diversity is Key
The number of LLMs have exploded recently and are on track to continue their explosive growth. This has led to a more diverse set of LLMs from which to choose, with key characteristics including:
- Open source or closed
- Speed
- Resource Requirements to Run
- Parameter Count
- Cost
- Performance
As LLM adoption grows more complex, the tradeoff between these different categories grows more complex as well. But these are all secondary considerations to performance. And this is where Threads can help you select the best LLMs so that you can better manage the tradeoffs between these categories.
Selecting the Best
Threads gives you access to a large list of LLMs (with custom LLM integration coming soon). After creating a Thread, you can easily run the Thread across multiple listed LLMs to begin comparing performance and analysis activities. While we are always adding more LLMs as well as the ability for you to bring custom and fine-tuned LLMs, our current standard offerings include:
- gpt-3.5-turbo
- llama-v2-70b-chat
- llama-2-70b-chat
- starchat-beta
- llama-2-13b-chat
- vicuna-13b
- codellama-13b-oasst-sft-v10
- oasst-sft-4-pythia-12b-epoch-3.5
- bloom
- llama-2-7b-chat
- dolly-v2-12b
- flan-t5-xl
- stablelm-tuned-alpha-7b
- codellama-13b
- oasst-sft-1-pythia-12b
- gpt-j-6b
- replit-code-v1-3b
- starcoder
- FalconLite
- WizardCoder-Python-34B-V1.0
- WizardLM-13B-V1.2
All LLMs that your Thread has been run on are listed on the Thread's overview page. You can see the status of runs (completed or queued).
Running LLMs
Threads makes it extremely easy to run an entire batch of different LLMs on a given Thread. Click here for details on how to run LLM on a Thread.
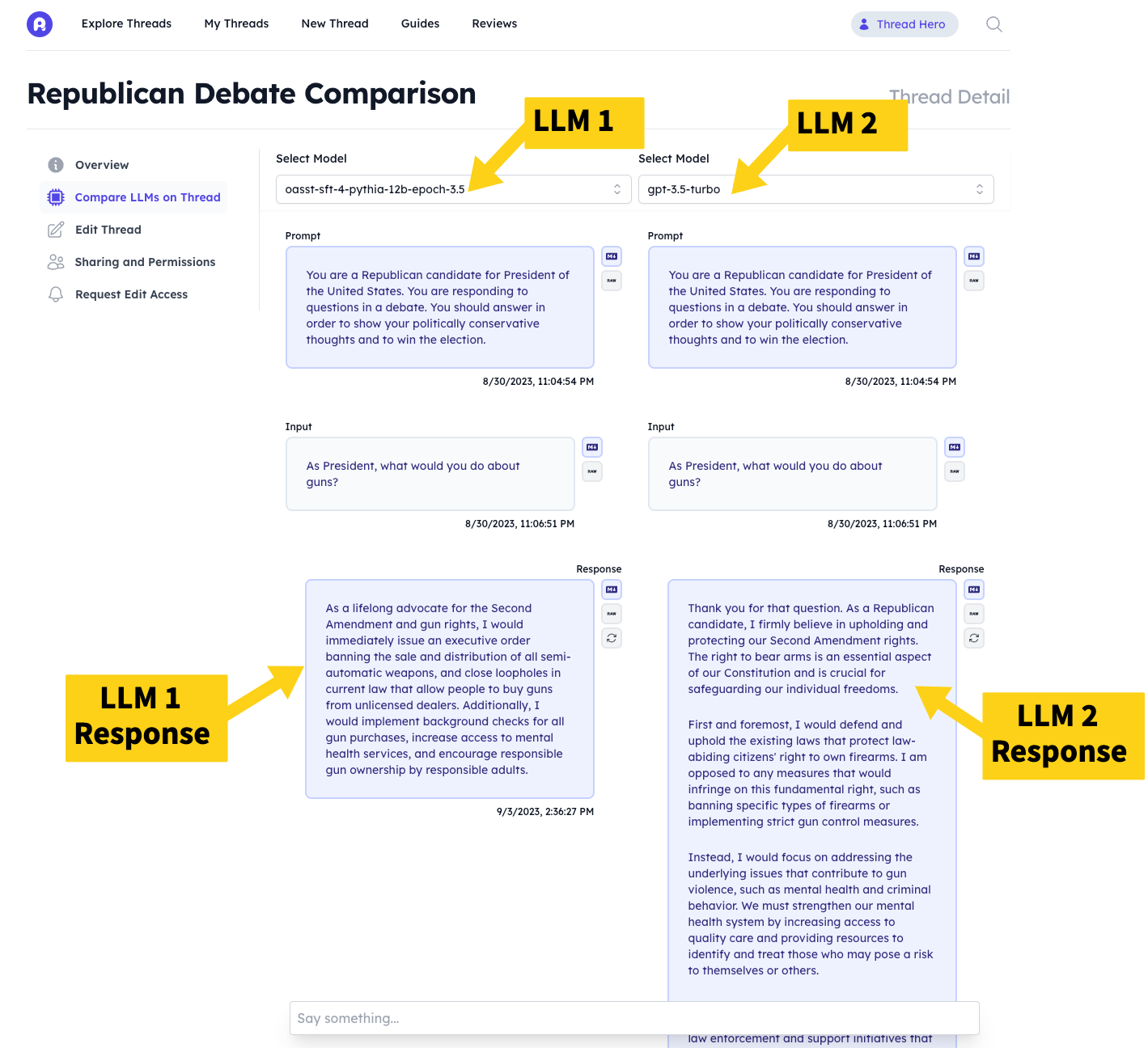
Comparing Performance
Once you have scheduled your Thread to run across multiple LLMs, you can easily compare the performance of the different LLMs on your Thread via the "Thread Compare" tab on the Thread's page. Because output length differs greatly between LLMs, the compare page beautifully displays each input/output pair in a standardized fashion to make it easier to understand.
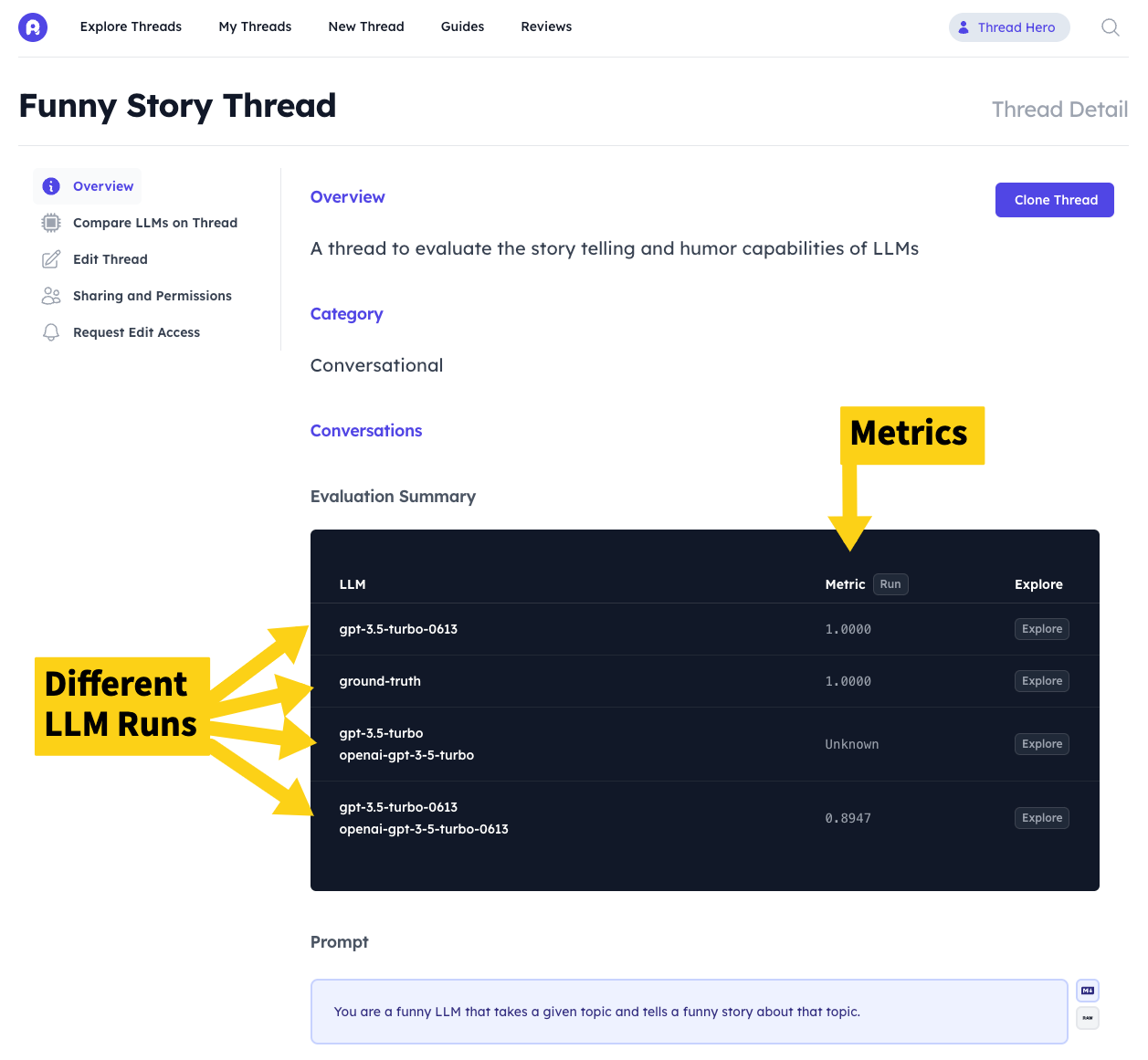
You can also see a quick snapshot comparison on different metrics on the Thread Overview page
Click here for more details on comparing the performance of Threads.